
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Community Tip - Your Friends List is a way to easily have access to the community members that you interact with the most! X
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Notify Moderator
How to score new data with ThingWorx Analytics 52.x till 8.0 ?
No ratings
The following is valid for ThingWorx Analytics (TWA) 52.0.2 till 8.0
For release 8.3.0 and above see How to score new data in ThingWorx Analytics 8.3.x ?
Overview
- The main steps are as follow:
- Create a dataset
- Configure the dataset
- Upload data to the dataset
- Optimize the dataset
- Create filters for training and scoring data
- Train the model
- Execute scoring on existing data
- Upload new data to dataset
- Execute scoring on new data
- TWA models are dataset centric, which means a model created with one dataset cannot be reused with a different dataset.
- In order to be able to score new data, a specific feature, record purpose in the below example, is included in the dataset.
- This feature needs to be included from the beginning when the data is first uploaded to TWA.
- A filter on that feature can then be created to allow to isolate desired data.
- When new data comes in, they are added to the original dataset but with a specific value for the filtered feature (record purpose), which allows to discriminate and score only those new records.
Process
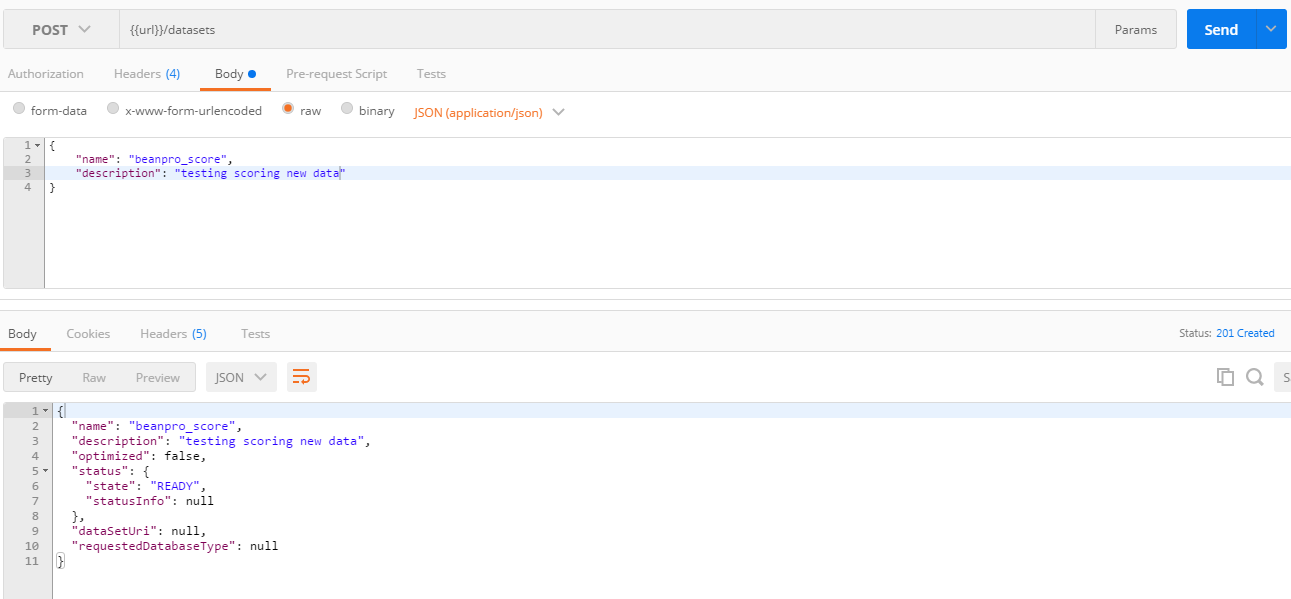
- Create a dataset
- This example uses the beanpro demo dataset
- Create dataset is done through a POST on datasets REST API as below
2. Configure dataset
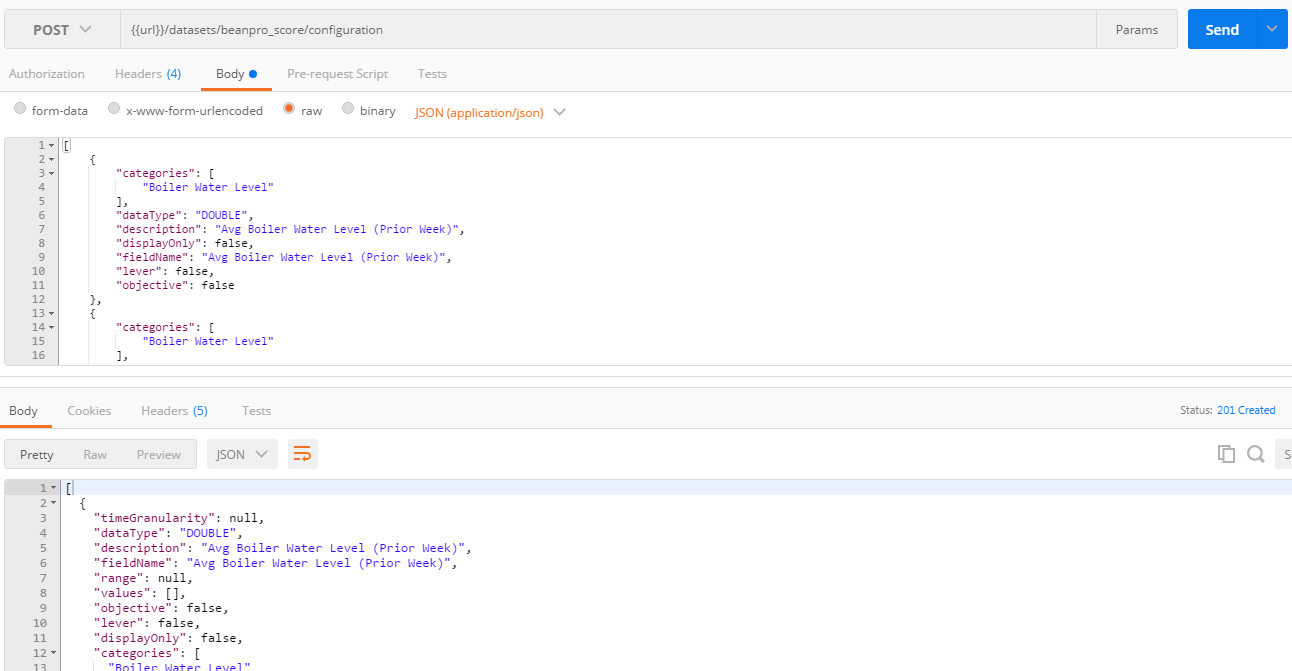
- This is done through a POST on <dataset>/configuration REST API
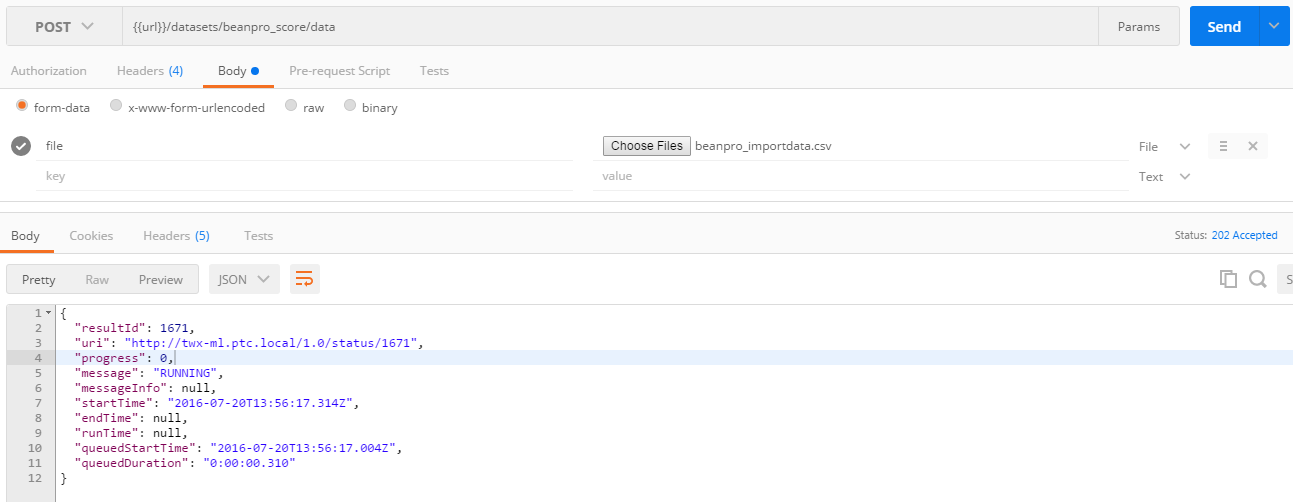
3. Upload data
4. Optimize the dataset

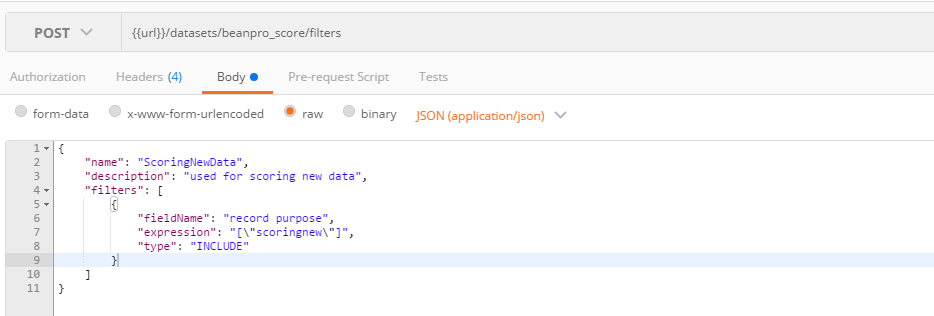
5. Create filters
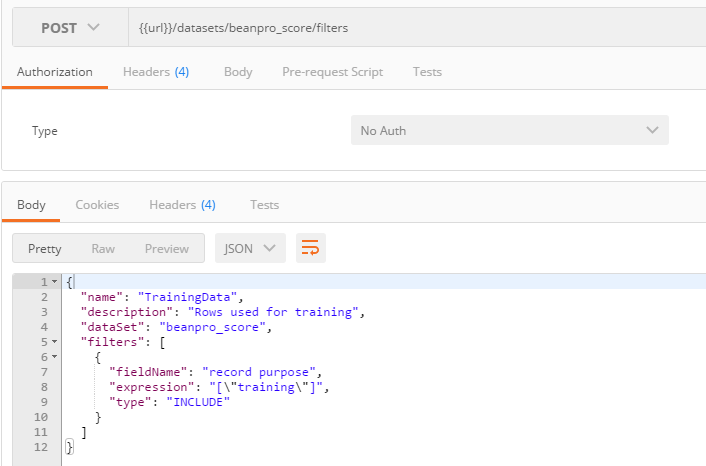
- The dataset includes a feature named record purpose created especially to differentiate between the rows to be used for training and the rows to be used for scoring.
- New data to be added will have record purpose set to scoringnew, which will allow to execute a scoring job limited to those filtered new rows
- Filter for training data:
- Filter for new scoring data
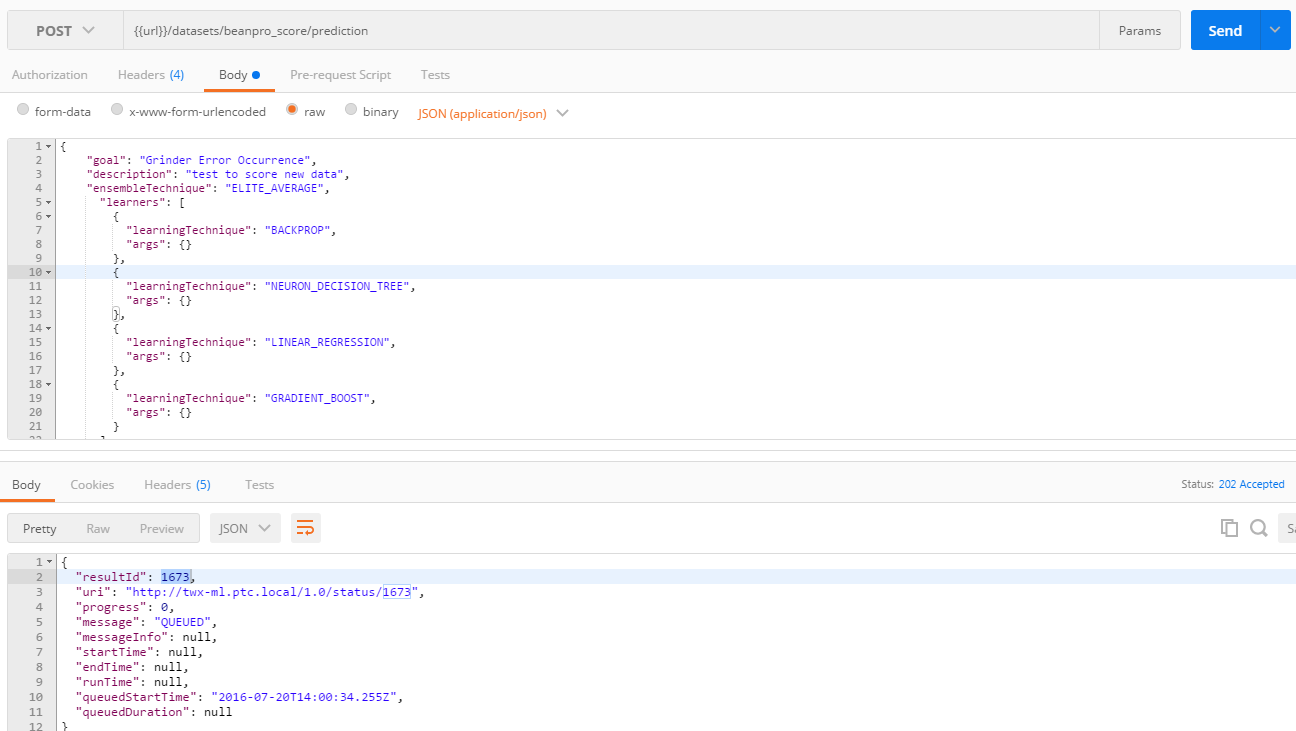
6. Train the model
- This is done through a POST on <dataset>/prediction API
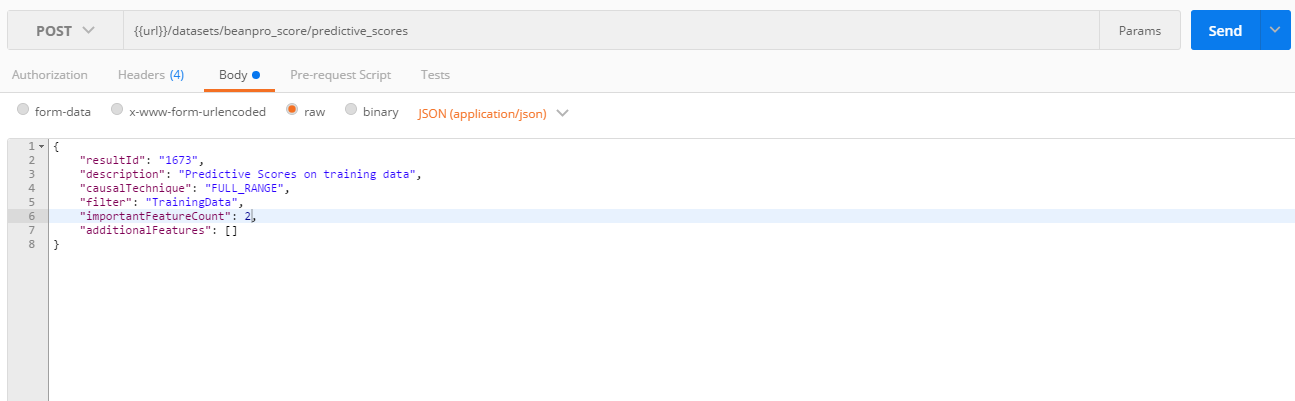
7. Score the training data
- This is done through a POST on <dataset>/predictive_scores API.
- Note the use of the filter TrainingData created earlier.
- This allow to score only the rows with training as value for record purpose feature.
- Note: scoring could also be done without filter at this stage, in which case all the data in the dataset will be scored and not just the ones with training fore record purpose
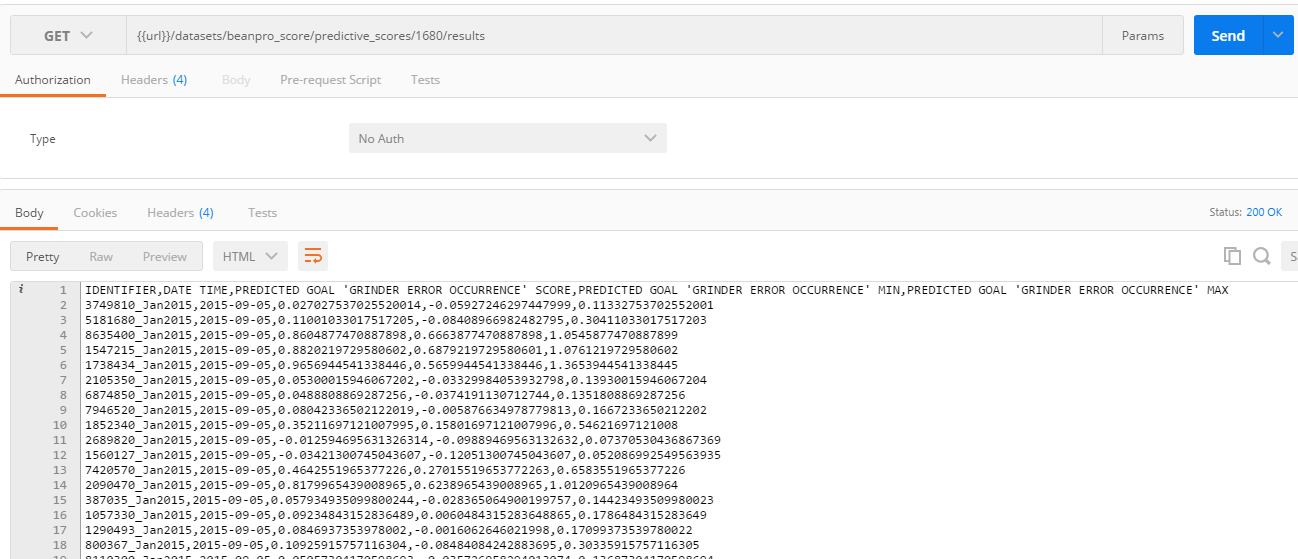
- Retrieving the scoring result show all the records in the dataset:
8. Upload new data
- The newly uploaded csv file should only contains new record.
- This will be appended to the existing ones.
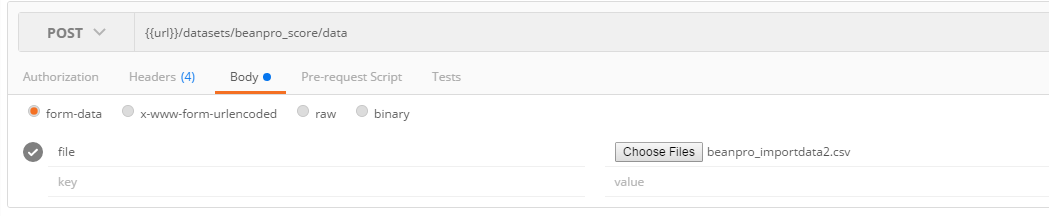
- Note that the new record (it could be more than one) has a value scoringnew for the record purpose feature:

- This will allow to use the previously created filter ScoringNewData so that a new scoring job will only take into account this new record.
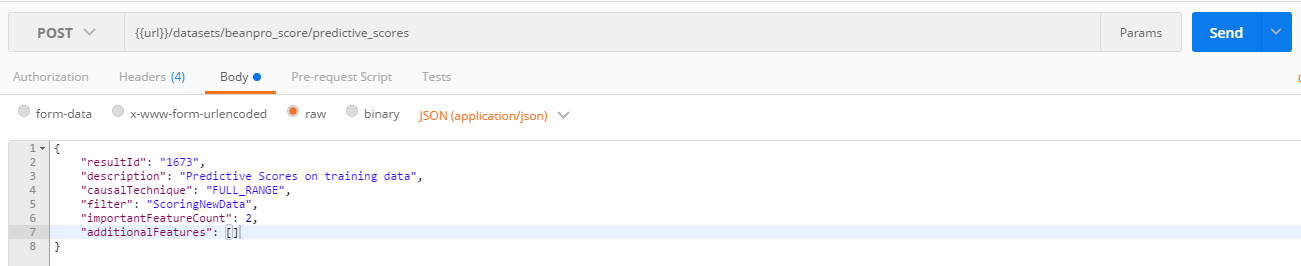
9. Scoring new data
- A POST on API predictive_scores is executed however using the filter ScoringNewData.
- This results in only the newly added data to be scored and therefore a much quicker execution time too.
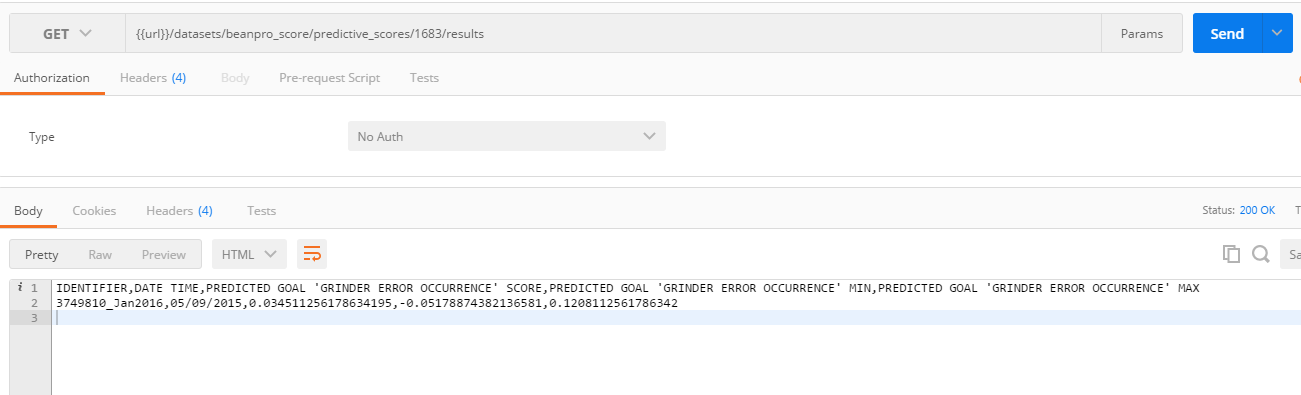
- Retrieving the scoring result shows only the new record:
Comments
Sep 04, 2017
10:08 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Sep 04, 2017
10:08 AM
Hi Christophe Morfin,
This is a very good tutorial indeed for beginners as compared to the one explained in the guide https://developer.thingworx.com/resources/guides/thingworx-analytics-quickstart
I followed all step mentioned above, but when I executed the step no 9 i.e. Scoring new data with filter ScoringNewData, I am getting the below error.
com.coldlight.ai.pmml.InvalidDataException: Unexpected value(s) found in Record with identifier: [71]. Feature [record_purpose] had value of [scoringnew]
I have used serial to uniquely identify rows, [71] is the row number 71.
Thanks,
Azim
Sep 04, 2017
11:20 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Sep 04, 2017
11:20 AM
Hi Azim
I think I know why you are getting this and you are bringing a good point, that seems to be missing in the blog.
The definition of the record_purpose field (or whatever name you gave it) needs to be defined with displayOnly set to true so that the algorithm knows to not take this field into account in the analysis.
Indeed for string feature, ThingWorx Analytics needs to have seen all possible values during training otherwise it will report an error "Unexpected value(s) found ..."
In your case if the record_purpose field is not set with displayOnly to true, you will need to create a new dataset with this change in the metadata json file.
The difinition woudl look something like this:
{
"dataType": "STRING",
"description": "record purpose",
"displayOnly": true,
"fieldName": "record_purpose",
"lever": false,
"objective": false
},
Hope this helps
Kind regards
Christophe
Sep 08, 2017
06:04 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Sep 08, 2017
06:04 AM
Hi Christophe Morfin,
The above solution had resolved the issue. However, as a beginner I am finding very difficulty to know the result as explained in step 9. What are these variables PREDICTED GOAL 'CONDITION' SCORE, PREDICTED GOAL 'CONDITION' MIN, PREDICTED GOAL 'CONDITION' MAX. What does they say. Can you please also share with us training and testing files. It will be really helpful for beginner to know all these parameter.
Thanks,
Azim
Sep 08, 2017
06:41 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Sep 08, 2017
06:41 AM
Hi Azim
The PREDICTED GOAL 'CONDITION' SCORE is probable the one you want to look at if you want a single value
PREDICTED GOAL 'CONDITION' MIN, PREDICTED GOAL 'CONDITION' MAX represent the range into which the predicted value can fall (remember this is using machine learning ie statistics ). Article Viewer | PTC might help here.
Also the Getting started article should be useful for you to find references: https://www.ptc.com/en/support/article?n=CS248832
Regards
Christophe
Nov 16, 2017
09:52 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Nov 16, 2017
09:52 AM
Hello Christophe Morfin,
I wanted to know currently what are the machine learning algorithm supported by Thingworx Analytics.
Thanks,
Azim
Nov 16, 2017
10:02 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Nov 16, 2017
10:02 AM
Hi Azim
You can find the answer at https://www.ptc.com/en/support/article?n=CS254667
Kind regards
Christophe
Dec 04, 2017
04:06 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Dec 04, 2017
04:06 AM
Hi Christophe Morfin,
How the pre processing of data is done in thingworx analytics. Like missing value treatment and outlier treatment for paramteric model and tunning and pruning for non paramteric model?
Does Optimize API of thingworx Analytics does the job for me?
Thanks,
Azim
Dec 04, 2017
06:28 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Dec 04, 2017
06:28 AM
Hi Azim
The following links should answer some of your questions:
https://www.ptc.com/en/support/article?n=CS228295
If you still have questions, I would suggest you open a case to Technical Support
Kind regards
Christophe
Dec 04, 2017
06:53 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Dec 04, 2017
06:53 AM
Hi Christophe Morfin,
Thanks for sharing this with me. Essentially the data has to be prepared before feeding the data into thingworx analytics.
Thanks,
Azim
