This blog is about Decision tree and it is aimed at providing the Analytics user with additional information about our default algorithm; Decision tree.
More specifically we will clarify what structures builds the Decision tree, understand the purpose of these structures, and last we will look at a few examples of pros and cons of applying Decision tree.
Decision tree is a great tool to help us making good decisions based on a huge amount of data. The algorithm maps information provided from the dataset and constructs a tree to predict our goal.
Classification and regression trees are the structures behind Decision tree – Therefore when we refer to Decision tree we collectively include classification and regression as being part of Decision tree.
But what is the difference between Classification and regression?
1) Classification can be used for predicting dependent categorical variables.
For example if needed to predict what type of failure occurs with a machine, or what type of car a person would buy it would be a classification tree.
2) Regression is used for dependent continues numerical variables.
For example if you want to predict the amount of sugar in a person’s blood or you need to predict the price of oil per gallon in 2020, regression is uses for the prediction.
Regression is addressing predictions, where the value can be continues valued, and classification tree predict the correct label/type for the class.
Example of a classification tree:
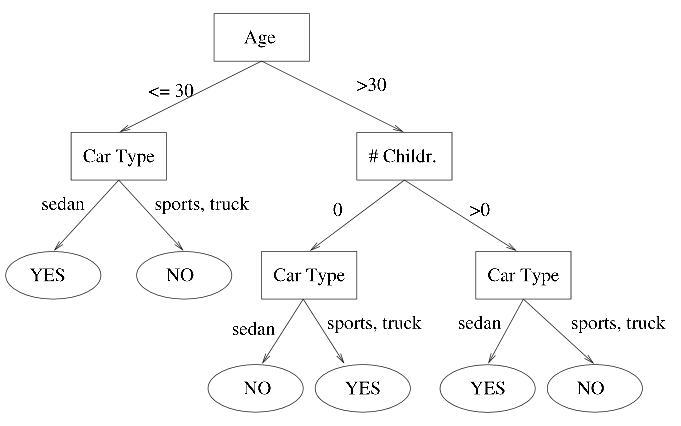
Keep in mind that it is the goal variable that determines the type of decision tree needed.
Using Decision tree is a powerful tool for prediction:
- Easy to understand and interpret.
- Help us to make the best decisions on the basis of existing information.
- Can handle missing values without needing to resort.
Considerations:
- As with all analytics models, there are also limitations of the decision tree.
- Users must be aware of, Decision trees can be subject to overfitting and underfitting, particularly when using a small dataset.
- High correlation between different variables may cause very high model accuracy.

