Parquet Data Format used in ThingWorx Analytics
Starting ThingWorx Analytics Version 8.1 Data storage will no longer require the installation of a PostgreSQL database. Instead, uploaded CSV data is converted to the optimized Apache Parquet format and stored directly in the file system.
This Blog explains some the features of Apache Parquet justifying this transition in ThingWorx Analytics Data Storage.
features
What is Apache Parquet:
Apache Parquet is a column-oriented data store of the Apache Hadoop ecosystem. It is compatible with most of the data processing frameworks in the Hadoop environment. It provides efficient data compression and encoding schemes with enhanced performance to handle complex data in bulk.
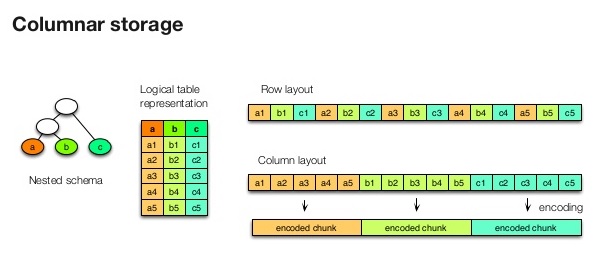
Below is an illustration of the Columnar Storage model:
Apache Parquet Features and Benefits:
Apache Parquet is implemented using the record shredding and assembly algorithm taking into account the complex data structures that can be used to store the data.
Apache Parquet stores data where the values in each column are physically stored in contiguous memory locations. Due to the columnar storage, Apache Parquet provides the following benefits:
- Column-wise compression is efficient and saves storage space
- Compression techniques specific to a type can be applied as the column values tend to be of the same type
- Queries that fetch specific column values need not read the entire row data thus improving performance
- Different encoding techniques can be applied to different columns

Some advantages of using Parquet for ThingWorx Analytics:
Apart from the above benefits of using Parquet which amount to higher efficiency and increased performance, below are some advantages that apply specifically to ThingWorx Analytics
- This change in ThingWorx Analytics from using a Database to using Parquet removes the limitations on the number of data columns the system can handle. It also allows for streamlining the dataset creation process.
- Since the data is converted to a Parquet format, there is no need to separately optimize the dataset. Even when new data is appended to an existing dataset, a new partition is added and re-optimization is optional but not required.
- Data could be appended easily so there is no longer a need to re-load the full Dataset when new Data values are added
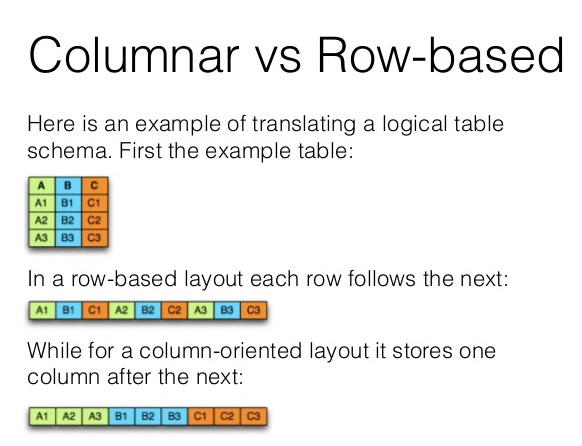
The illustration below shows the transition from Row-based Data Storage model VS the columnar based Storage of Parquet